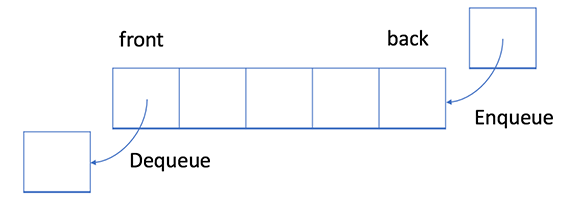
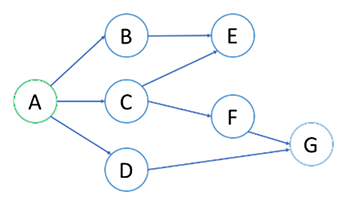
结点的处理顺序是什么? 在第一轮中,我们处理根节点。在第二轮中,我们处理根结点旁边的结点;在第三轮中,我们处理距根节点两步的结点。 与树的层序遍历类似,越是接近根节点的结点越早遍历。 如果在第 K 轮中将结点 X 添加到队列中,则根节点与 X 之间的最短路径长度恰好是 K,也就是说,第一次找到目标结点的时候,你已经处于最短路径中了。
/** * 返回根节点和目标节点之间最短路径的长度。 */ intBFS(Node root, Node target){ Queue<Node> queue; // 存储所有等待处理的节点 int step = 0; // 从根到当前节点所需的步骤数 // 初始化 add root to queue; // BFS(广度优先搜索) while (queue is not empty) { step = step + 1; // 迭代队列中已经存在的节点 int size = queue.size(); for (int i = 0; i < size; ++i) { Node cur = the first node in queue; return step if cur is target; for (Node next : the neighbors of cur) { add next to queue; } remove the first node from queue; } } return-1; // 从根到目标没有路径 }
如代码所示,在每一轮中,队列中的结点是等待处理的结点。
在每个更外一层的 while 循环之后,我们距离根结点更远一步。变量 step 指示从根结点到我们正在访问的当前结点的距离。
/** * 返回根节点和目标节点之间最短路径的长度。 */ intBFS(Node root, Node target){ Queue<Node> queue; // 存储所有等待处理的节点 Set<Node> used; // 存储所有使用的节点 int step = 0; // 从根到当前节点所需的步骤数 // 初始化 add root to queue; add root to used; // BFS(广度优先搜索) while (queue is not empty) { step = step + 1; // 迭代队列中已经存在的节点 int size = queue.size(); for (int i = 0; i < size; ++i) { Node cur = the first node in queue; return step if cur is target; for (Node next : the neighbors of cur) { if (next is not in used) { add next to queue; add next to used; } } remove the first node from queue; } } return-1; // 从根到目标没有路径 }