今天发现总结的比我学的慢,说明学的有点心急了,不慌慢慢来。
栈和深度优先搜索 与 BFS 类似,深度优先搜索(DFS)也可用于查找从根结点道目标结点的路径。
1.结点的处理顺序是什么?
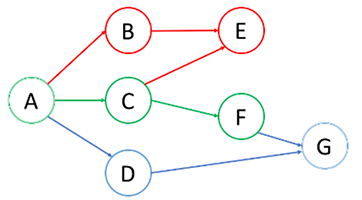
在下图中,从根结点 A 开始。首先选择结点 B 的路径,并进行回溯,直到到达结点 E,无法更进一步。然后回溯到 A 并选择第二条路径到结点 C。从 C 开始,我们尝试第一条路径到 E 但是 E 已被访问过。所以我们回到 C 并尝试从另一条路径到 F。最后找到 G。
总的来说,在我们到达最深的结点之后,我们只会回溯并尝试另一条路径。
因此我们在 DFS 中找到的第一条路径不一定就是最短的路径。例如,在上面的例子中,我们成功找出了路径 A->C->F->G 并停止了 DFS。但这不是从 A 到 G 的最短路径。
2.栈的入栈和退栈顺序是什么?
结点的处理顺序是完全相反的顺序,就像它们被添加到栈中一样,它是后进先出(LIFO)。这就是我们在 DFS 中使用栈的原因。
DFS-模版-1 在大多数情况下,我们在能使用 BFS 时也可以使用 DFS。但是有一个重要的区别:遍历顺序
与 BFS 不同,更早访问的结点可能不是更靠近根结点的结点。因此,你在 DFS 中找到的第一条路径可能不是最短路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 boolean DFS (Node cur, Node target, Set<Node> visited) return true if cur is target; for (next : each neighbor of cur) { if (next is not in visited) { add next to visted; return true if DFS (next, target, visited) true ; } } return false ; }
当我们递归地实现 DFS 时,似乎不需要使用任何栈。但实际上,我们使用的是由系统提供的隐式栈,也称为调用栈(Call Stack)
题目:岛屿数量 岛屿数量又来了,大多数情况下,能用 BFS 解决的问题,也能被 DFS 解决。问题具体见。岛屿问题
代码如下(C++):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution { private : void dfs (vector <vector <char >> & grid,int r,int c) int nr = grid.size(); int nc = grid[0 ].size(); grid[r][c] = '0' ; if (r-1 >=0 && grid[r-1 ][c] == '1' ) dfs(grid,r-1 ,c); if (r+1 <nr && grid[r+1 ][c] == '1' ) dfs(grid,r+1 ,c); if (c-1 >=0 && grid[r][c-1 ] == '1' ) dfs(grid,r,c-1 ); if (c+1 <nc && grid[r][c+1 ] == '1' ) dfs(grid,r,c+1 ); } public : int numIslands (vector <vector <char >>& grid) int nr = grid.size(); if (!nr) return 0 ; int nc = grid[0 ].size(); int num_island = 0 ; for (int r = 0 ; r < nr; ++r){ for (int c = 0 ; c < nc; ++c){ if (grid[r][c] == '1' ){ ++num_island; dfs(grid,r,c); } } } return num_island; } };
题目:克隆图 给你无向连通图中一个节点的引用,请你返回该图的深拷贝(克隆)
1 2 3 4 class Node { public int val; public List<Node> neighbors; }
说白了,看了半天没懂,大概意思就是说???拷贝一个图?参考了别人的代码,自己还是没理解。等再看看。
代码如下(C++):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : Node* cloneGraph (Node* node) { unordered_map <Node*,Node*> mp; return dfs(node,mp); } Node* dfs (Node* node,unordered_map <Node*,Node*> &mp) { if (!node) return NULL ; if (mp.count(node)) return mp[node]; Node* tmp = new Node(node -> val); mp[node] = tmp; for (Node* neighbor: node -> neighbors){ tmp -> neighbors.push_back(dfs(neighbor,mp)); } return tmp; } };
目标和 给定一个非负整数数组,a1,a2,…,an,和一个目标数 S。现在你有两个符号+和-。对于数组中的任意一个整数,你都可以从+或-中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
示例:
1 2 3 4 5 6 7 8 9 输入:nums: [1, 1, 1, 1, 1], S: 3 输出:5 解释: -1+1+1+1+1 = 3 +1-1+1+1+1 = 3 +1+1-1+1+1 = 3 +1+1+1-1+1 = 3 +1+1+1+1-1 = 3 一共有5种方法让最终目标和为3。
提示:
数组非空,且长度不会超过 20 初始的数组的和不会超过 1000 保证返回的最终结果能被 32 位整数存下 使用递归,枚举出所有可能的情况。具体地,当我们处理到第 i 个数时,我们可以将它添加+或-,递归地搜索这两种情况。当我们处理完所有的 N 个数时,我们计算出所有数的和,并判断是否等于 S。
代码如下(C++):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : int findTargetSumWays (vector <int >& nums, int S) return dfs(nums,S,0 ); } int dfs (vector <int > &nums,uint target,int left) if (target == 0 && left == nums.size()) return 1 ; if (left >= nums.size()) return 0 ; int ans = 0 ; ans += dfs(nums,target-nums[left],left+1 ); ans += dfs(nums,target+nums[left],left+1 ); return ans; } };
DFS-模版-2 递归解决方案的优点是它更容易实现。但是,存在一个很大的缺点:如果递归的深度太高,你将遭受堆栈溢出。在这种情况下,您可能会希望使用 BFS,或使用显式栈实现 DFS。
模版(JAVA):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 boolean DFS (int root, int target) Set<Node> visited; Stack<Node> s; add root to s; while (s is not empty) { Node cur = the top element in s; return true if cur is target; for (Node next : the neighbors of cur) { if (next is not in visited) { add next to s; add next to visited; } } remove cur from s; } return false ; }
该逻辑与递归解决方案完全相同。但使用了 while 循环和栈来模拟递归期间的系统调用栈。
二叉树的中序遍历 给定一个二叉树,返回它的中序遍历。
首先得知道什么是中序遍历:
二叉树的遍历方式有前序,中序,后序,层序
接下来就好理解了,左根右,递归。
代码如下(C++):
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public : vector <int > ans; vector <int > inorderTraversal (TreeNode* root) if (root != NULL ){ inorderTraversal(root -> left); ans.push_back(root -> val); inorderTraversal(root -> right); } return ans; } };
声明:本文为学习记录,参考之处较多,如果有侵权内容,请联系我立即删除 。
BTW: 端午节快乐~